Why you should consider low-code for data science?
In 2022, data analysis will be critical to the success of every business. According to a global report by EY, 81% of CEOs think data should be at the center of all decision-making. In a typical data science process, companies might encounter some common challenges.
First, you have to manage vast amounts of unstructured data when building applications. According to statistics conducted via various industries, they account for 80-90% of total input data. Also, applications generate logs in multiple formats, making it difficult to standardize disparate formats before they can be used in ML applications.
Another consideration is the sheer difficulty of developing ML/AI applications. As a company creates more data, it should be able to evaluate trends to better understand the impact of features and improve customer experiences.
Most digital apps can benefit from AI capabilities such as sentiment analysis and image classification. Data collection, cleansing, model training, feature engineering, exploratory data analysis, and other advanced techniques are required. Indeed, machine learning is the most in-demand AI skill, making access to such talent harsh for developers.
This is when low-code comes in clutch. This technology consists of pre-built code blocks that you can drag into places to create a simple application without touching a line of code.
Yet, unlike simple software builders, low-code data science tools allow you to customize the front-end and back-end accordingly to your requirements. This ensures flexibility and scalability. By saving time on software development, you can focus on training your data model and customizing a data services worker.
Discover the advantages of opting for Low-code AI over its conventional counterpart
How data department leverage the best of low-code?
1. Low-code for data engineers
A low-code environment enables data professionals to construct those data views electronically and, on the go, and then hand them over to their consumers. Data engineers can create internal data sources that adhere to governance requirements, while their users can use the same environment to further personalize the data view to match their needs.
The data engineers can even swap from one data source, like their current cloud storage provider, to another or add a new source without their users seeing it. As a result, the data engineers can constantly deliver new and updated views to their virtual data warehouse.
In the end, what data engineers do is essentially visual SQL programming. They can even reach out and give actual code samples if they like, although, in a well-designed low-code environment, this is rarely required.
2. Low-code for data scientist
Many coding environments are either too sophisticated or far too simple to suit the breadth of a data science team’s requirements. A data scientist typically desires precise control over a learning algorithm’s little knobs and dials and the ability to select from an extensive library of methodologies.

The low-code environment allows data scientists to:
- More flexible with the tools they employ.
- Allow them to concentrate on the more fascinating aspects of their job while abstracting away from tool interfaces and multiple versions of related libraries.
- Reach out to deeper coding if they like
- Access to new technologies, making it future-proof for ongoing advances in the field
- Include a mechanism for packaging and deploying trained models.
- Have all the essential processes for data transformations into production.
3. For better collaboration between data departments with business user
Typically, the interaction between the data science department and its end users is tense. The business did not obtain what it desired, and the data science team did not receive credit. A low-code environment can assist the data science team talk with the business about how they intend to arrive at the answer intuitively and visually. The business users just need to comprehend the data flow and provide immediate feedback if any issues exist.
The low-code data science platform also provides a considerably faster turnaround for the data science team; changes to the data flow are rapid and easy. As a result, data science is no longer performed in isolation but rather as part of a collaborative effort that effectively leverages the experience of both data and business specialists.
Use cases to integrate low-code into your data science
Low-code platforms cover various operations to solve your problems. Visual programming has enabled everyone to perform these functions. Some specific use cases can be accomplished through low-code data science platforms.
Collecting the data
Data science starts with the collection of data. Low-code platforms can integrate APIs to automatically collect data from your web sources. Data scraping has become relatively more accessible, and these services require no infrastructure.
If you are a new business with a smaller team, you don’t need to worry about developing in-house servers and databases to facilitate data collection. Low-code provides you with pre-built connectors that allow you to access several data sources on the internet.
This could be an internal database, or an external system provided by a third party. You may quickly extend the number of data sources using pre-built connectors and improving your algorithm. When acting on data in real-time, programmatic, automatic interactions become even more vital.
You can quickly connect all your data by integrating your platform with other systems using These 9 Low-code API Builders
Giving data structure
A significant amount of data on the internet is unstructured. Structure your data to acquire insights by deleting erroneous, incomplete, incorrectly structured, or duplicated data. This is often referred to as data cleansing.
Automation can be used with low-code platforms to purify and make data readable. The drag-and-drop interface allows you to create visual automation for regularly cleaning your data using bots.
Visual automation For Training And Deploying Machine Learning Solutions
Data science is more than just collecting, organizing, and reading data. Deep learning, machine learning, and AI are used to perform many complicated functions in this area.
Numerous low-code libraries can help data scientists with various training elements and deploy ML with less code. PyCaret, for example, offers complete ML model development. Other programs include Auto-ViML, CreateML, RunwayML, and Teachable Machine from Apple. Some may require Python or R knowledge to fully use, but others are more codeless.
Data Visualization And Gathering Business Insights
This is the most appealing component of data science for co-founders and business users. Using low-code data science platforms, you can get business insights from cleaned data and trained machine learning models.
Although it is seldom the primary function of a low-code program, it is a very useful supporting function. Visualize your business data and insights in a visually appealing style created from your dataset.
Moreover, to better reduce the barriers to data organization. Drag-and-drop features in its interfaces could substantially aid in the organization and structure of data with usable flows.
Give Amateurs No-code AutoML
Many libraries and no-code platforms can use raw data to train an algorithm. The use of such platforms has the potential to democratize sophisticated machine-learning capabilities. Google Cloud AutoML, Ludwig by Uber AI, Baidu’s EZDL, and Obviously.ai are all no-code AutoML platforms.
Create Dashboards And Reports
In addition to ML/AI preparation, low-code can assist data scientists in creating visualizations of their data. This could be useful for quarterly evaluations or auditing an organization’s data footprint. Many low-code development platforms have modules for creating visually appealing user interfaces and visualizations based on a dataset.
- Explore further: Centralize Everything With Low-code Data Integration: Top 5 Tools
Top low-code data science platform
1. PyCaret
PyCaret enables data professionals to quickly and easily construct and deploy machine learning models. The breadth of functionality, including data preparation, model training, and evaluation, makes this the low-code library of choice. Model deployment and hyperparameter tuning are two more popular features of PyCaret. All of this is managed through a single interface with built-in visualization tools that assist those developing models in better understanding both data and results.
One of the key reasons for the popularity of this low-code data engineering is that PyCaret minimizes the amount of code required to build a machine learning model. This allows data scientists to focus on other areas of their projects that may require greater attention.
Because PyCaret does much of the heavy lifting, novices can dip their toes in the waters of machine learning without a comprehensive understanding of underlying algorithms and approaches. This lowers the skill entry point, making it easier for non-traditional data scientists interested in machine learning models to get started.
2. H2O AutoML
The platform offers the users a set of algorithms and tools to automate the machine learning workflow. This includes everything from data prep through model deployment. The goal of this low-code tool is to make it simple for data scientists to develop highly accurate machine-learning models without requiring considerable manual work.
Similar to PyCaret, some components are automated, such as feature engineering, hyperparameter tuning, and model selection. One notable feature of H2O AutoML is its capacity to handle massive data sets with relative ease and to scale horizontally across several machines, making it an ideal fit for big data applications. That is how H2O AutoML can support various machine learning applications like regression, time-series forecasting, anomaly detection, and classification.
3. Auto-ViML

This open-source low-code data science is developed on top of the sci-kit-learn, Pandas, and NumPy libraries to simplify developing machine learning models. One advantage is a simple interface that allows users to quickly create highly realistic models. As a result, Auto-ViML successfully automates many laborious and time-consuming activities involved in machine learning, allowing users to rapidly and efficiently develop highly accurate models.
Auto-ViML‘s key advantages include its ease of use and the reduced coding required for entry into model construction. This is because it requires very little code and configuration. As a result, Auto-ViML is an excellent tool for beginners and specialists. It also supports various machine learning applications, such as regression, classification, and time-series forecasting.
4. TPOT (Tree-based Pipeline Optimization Tool)
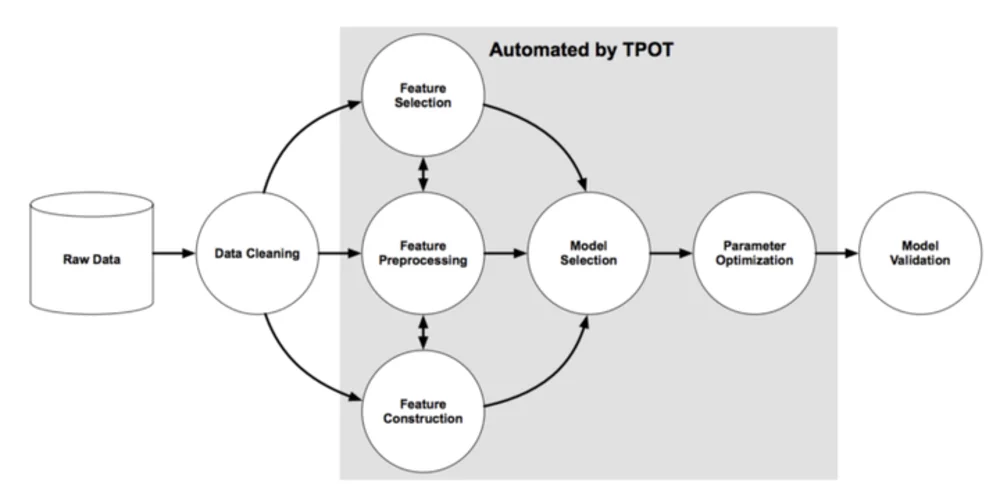
TPOT uses a tree-based representation of the pipeline space and generates many potential pipelines. The pipelines are then evolved across several generations utilizing programming approaches to optimize them against a specific problem.
This low-code data management tool focuses on usability, offering users a straightforward interface that removes much of the laborious and time-consuming effort from machine learning while still swiftly establishing highly accurate models.
5. AutoKeras
The model section, architecture search, and hyperparameter adjustment are all features included in this low-code data science. AutoKeras employs a technique known as neural architecture search or NAS. This search for the optimum neural network for every given task is automated.
AutoKeras’ capacity to handle organized and unstructured data is intriguing. It can take data preprocessing automatically, including encoding, imputation, and data normalization, making it easier for users to develop models with different data types.
6. Power BI
This powerful low-code data visualization product from Microsoft is granted as the top leader for Analytics and BI platforms. Power BI provides specialized tools and a robust coding environment to translate your data into actionable insights and engaging visuals.
Powered by AI, namely the Copilot features, it can automatically analyze and visualize data, saving you time from manual and tedious tasks. Power BI is a huge plus for Microsoft users, as you can connect, transfer and centralize your data system across other applications, such as Microsoft365 or SharePoint.
Synodus is the certified partner of Microsoft Power BI. We have helped multiple businesses, from retail to financial, to transform their data management using Power BI and extensive data tools.
What to aware when using low-code data science platform
When it comes to data science, the traditional programming technique has several advantages over low-code platforms.
- Customization is a problem because low-code makes constructing highly customized models and algorithms harder. If you have complex data challenges, the traditional technique may be necessary.
- Debugging: If an error occurs, it becomes difficult to debug the code. Traditional code provides more visibility into what’s happening and where things may fail.
- Scalability: Optimizing low-code for performance might be more complex, and you may not achieve the same level of speed and efficiency as you would with traditional coding.
Low-code data science can help knowledge workers in various positions solve their challenges. Though low-code lowers the barrier to entry, it will not, in many circumstances, replace or eliminate the requirement for professionals or technical contributors. Consider its benefits and practical applications ahead of time for better results when using it in your firm.
More related posts from Low-code blog you shouldn’t skip:




