Key takeaway
- PRs created by autonomous AI agents take 5.3 times longer for a human to pick up and review than unassisted PRs, making code review the new primary bottleneck in software delivery (LinearB, 2026)
- 90% of technology professionals now use AI at work, but higher AI adoption is currently associated with increased software delivery instability, not less (DORA, 2025)
- Junior developers with less than one year of experience take 7% to 10% longer to complete tasks with AI in some situations because they lack the foundational knowledge to verify the machine’s output (FSE, 2025)
- Measuring productivity by lines of code is now actively counterproductive. CTOs must shift to DORA metrics to evaluate whether AI is improving system performance or just accelerating output volume
The gap between what CTOs see and what engineers experience
There is a consistent divide in how different levels of an engineering organization perceive AI.
CTOs see developers producing code faster. They see prototypes built in two days that previously took two weeks. They see productivity dashboards trending upward. The case for AI investment looks straightforward.
Engineers see something different. New delays at the review stage. Hours spent debugging AI-generated code that looked correct but was not. A growing gap between what the machine produces and what the production environment actually requires.
Both perceptions are accurate. They are describing different parts of the same process.
According to the 2025 DORA State of AI-assisted Software Development report, 90% of technology professionals now use AI at work, and over 80% believe it increases their productivity. The same report found that higher AI adoption is associated with increased software delivery instability.
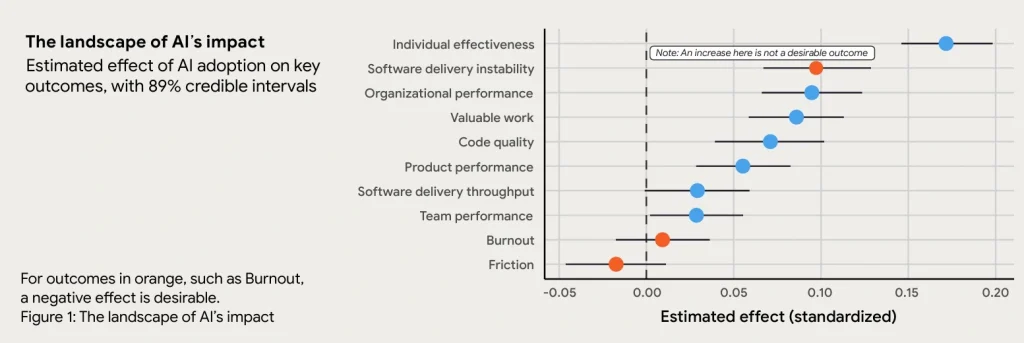
This is not a contradiction. AI does not fix broken processes. It amplifies whatever process it operates within. If an organization has clear workflows, strong testing practices, and experienced engineers who can evaluate machine output, AI accelerates delivery without degrading quality. If a team has poor governance, isolated data, and junior-heavy composition, AI helps them generate technical debt and errors faster.
The SDLC does not need more AI. It needs the people working within it to change how they engage with AI at every level: engineer, tech lead, and CTO.
What engineers must change: maintain the ability to evaluate, not just generate
For individual developers, AI removes the friction of starting. It writes standard code instantly, explains unfamiliar concepts, and fills in boilerplate that previously consumed hours. The productivity gain is real.
The structural problem is also real. When AI lowers the barrier to entry, junior engineers skip the problem-solving phase that is where software engineering competence is built. If an AI provides code that looks correct, the path of least resistance is to accept it and move to the next task, without debugging it, without understanding the underlying architecture, without knowing whether it fits the broader system.
A 2025 paper presented at the Foundations of Software Engineering conference documented this directly. Junior developers with less than one year of experience took 7% to 10% longer to complete tasks with AI assistance in some situations. The reason: they lacked the foundational knowledge to identify when the AI was wrong, so they spent hours attempting to fix suggestions that a more experienced engineer would have immediately recognized as incorrect.
The principle this establishes applies across experience levels: AI is only as useful as the engineer’s ability to evaluate its output. A developer who cannot read and verify the code an AI generates will eventually lose the ability to produce code without it, which creates a fragile dependency rather than a productivity gain.
What this means in practice
Engineers should treat AI as a drafting tool that requires expert review, not a delivery mechanism that removes the need for one. The critical discipline is maintaining the habit of reading, understanding, and modifying AI-generated code rather than accepting and committing it. The evaluate and modify steps cannot be skipped without cost. They are where the engineer’s judgment replaces the machine’s limitations.
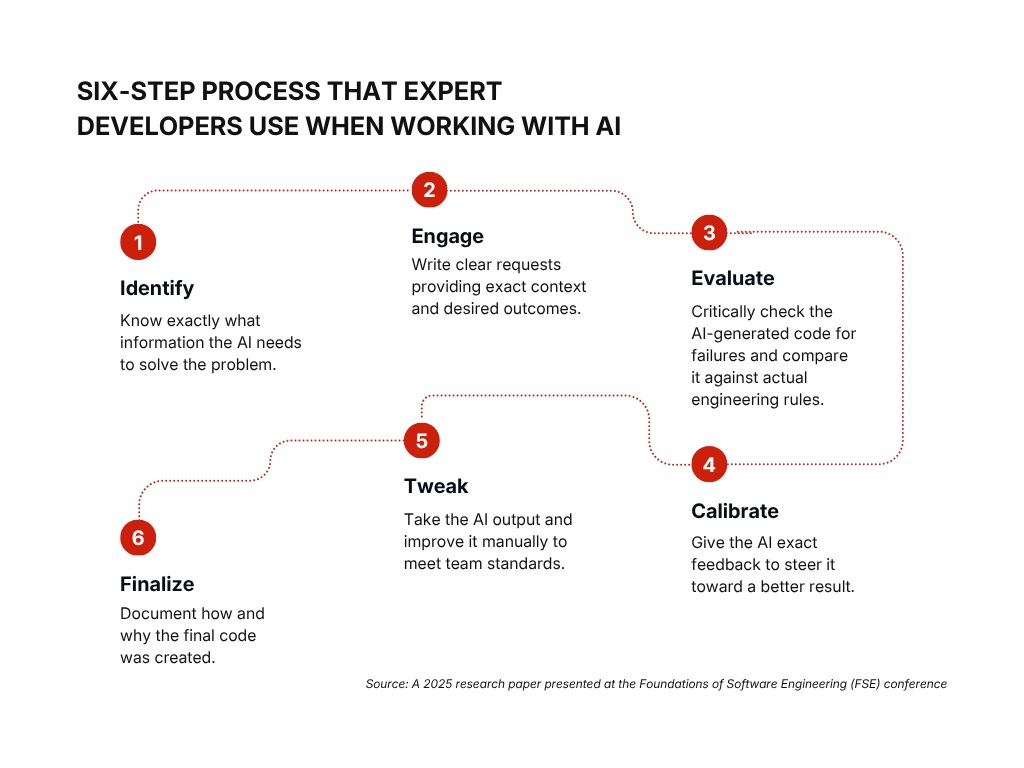
For teams managing junior developers, this has a specific implication: AI adoption without foundational skill development will produce engineers who are dependent on a tool they cannot oversee. The investment in teaching engineers to evaluate AI output is not optional. It is what makes AI adoption sustainable.
What tech leads must change: fix the review bottleneck before it stalls your releases
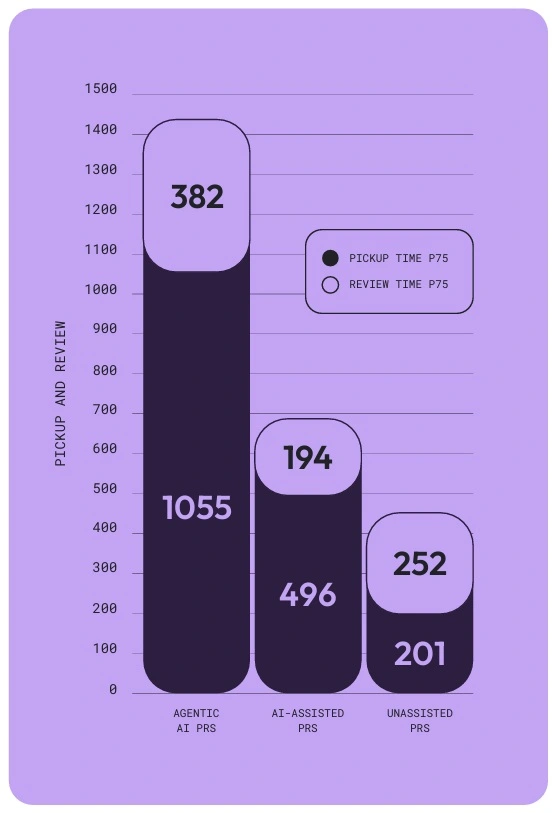
Writing code is faster. Reviewing it has become the dominant constraint in the delivery cycle, and the data quantifies exactly how severe that constraint is.
LinearB analyzed over 8 million pull requests to measure how AI affects the review stage. The findings are specific: PRs created by autonomous AI agents take 5.3 times longer for a human to pick up and review than unassisted PRs. AI-assisted PRs, where a developer used AI but submitted the work themselves, take 2.47 times longer.
The reason is cognitive loads. Reviewing code written by another human carries implicit trust. You can follow the reasoning, recognize familiar patterns, and assess intent. Reviewing machine-generated code requires treating every line as potentially incorrect, because AI presents wrong answers with the same confidence it presents correct ones. The 2025 DORA report found that 30% of developers currently report little to no trust in AI-generated code. Reviewers know this. The mental effort required to review AI code properly is significantly higher than reviewing human code.
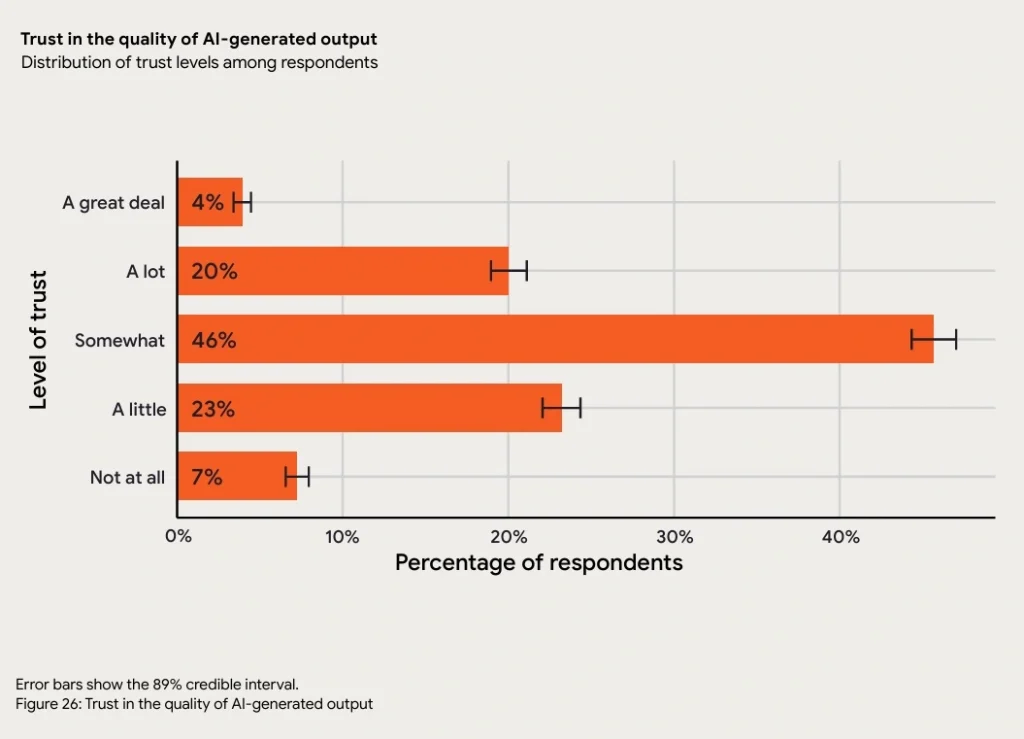
When PRs sit unreviewed for days because senior engineers cannot absorb the review load, the engineers who wrote them lose context. Rework increases. Release cycles slow down despite AI making the writing phase faster. The speed gain at the front of the process is consumed by delay at the review stage.
What this means in practice
The most effective structural change tech leads can make is to require that AI validates AI before a human reviewer sees the code. Running an automated AI review tool in the pipeline to catch syntax errors, formatting issues, and obvious logic failures means the human reviewer starts from a higher baseline – focused on business logic, security requirements, and system fit rather than basic code quality.
The second structural change is requiring engineers to explain their architectural decisions in code comments before submitting for review. A human reviewer should not have to reverse-engineer why a specific approach was chosen. If the author cannot articulate why the code is structured in the way it is, the review process will surface that gap at significant cost to the reviewer’s time.
The third is requiring test cases before a PR can be submitted. Code without tests is a hypothesis. Code with tests is a verified claim. Requiring engineers to generate test cases for AI-produced code before human review creates a quality gate that catches the most common AI failure modes before they consume a senior engineer’s attention.
What CTOs must change: measure system performance, not code volume
For CTOs, AI makes the beginning of a project look exceptionally fast. A prototype that previously took two weeks can be assembled in two days. The early metrics are compelling.
The problem emerges in the final stretch. Moving from prototype to a live, secure production environment requires handling rare edge cases, integrating with existing internal systems, and verifying that the new code behaves correctly within the full operational context of the business. AI struggles significantly with this phase, not because it cannot generate code, but because it lacks the business context required to generate the right code.
LinearB’s analysis makes this concrete: AI provides the largest productivity gains on new projects with clean codebases. The more complex and specific the existing system (legacy databases, proprietary business logic, compliance-specific workflows) the smaller the productivity gain from AI. A generic AI tool does not understand a company’s specific five-year-old database structure. It generates code that compiles but fails in production because it does not know what the system requires.
This has a direct implication for how CTOs measure engineering performance. Because AI generates code volume effortlessly, measuring productivity lines of code is not just inaccurate. It is actively harmful. Engineers assessed on output volume will use AI to generate volume. The metric will look healthy. The system underneath it will deteriorate.
What this means in practice
DORA metrics measure what actually matters – system performance rather than developer activity. Deployment frequency tells you whether releases are getting more consistent. Change lead time tells you whether the full delivery cycle is improving, not just the writing phase. Change failure rate tells you whether AI-assisted code is making it to production in good condition or generating incidents. Failed deployment recovery time tells you whether the system architecture is sound enough to recover quickly when something goes wrong.
If deployment frequency is increasing but change failure rate is rising at the same time, AI is accelerating delivery of defects, not improving engineering performance.
The second priority for CTOs is closing the context gap that makes AI fail at the production stage. Generic AI tools fail because they lack access to the specific rules, past decisions, and system constraints that govern how a company’s software must behave. Giving AI tools secure, structured access to internal documentation, historical decision records, and existing codebases is the engineering investment that makes AI useful in production environments, not just in prototyping.
Speed without judgment creates technical debt at scale
AI makes software development faster. It does not make it better on its own.
If engineers skip the evaluation step, senior developers absorb a review load they cannot sustain. If tech leads do not restructure how reviews work, the speed gains at the writing stage are consumed by delays at the review stage. If CTOs measure lines of code rather than system outcomes, they optimize for a metric that now means nothing and miss the signals that indicate real delivery health.
At Synodus, 87% of our engineers are mid-level and senior professionals. This is not a preference. It is a functional requirement for the industries we work in. When we built an automated credit processing system for BOC Aviation, the productivity gain did not come from generating more code faster. It came from engineers who understood BOC Aviation’s credit processes well enough to design the system correctly before writing a line of code. Processing time went from ten days to two days. The AI assisted. The senior engineers governed what it produced.
In banking, healthcare, and the public sector, the cost of a production failure is not a delayed sprint. It is a compliance event, a data breach, or a system outage that affects real operations. AI does not know the difference between code that compiles and code that is safe to run in those environments. Experienced engineers do.
The organizations that build durable engineering advantages from AI in 2026 will not be the ones that adopt it most aggressively. They will be the ones that build the governance, team composition, and measurement frameworks that make AI output trustworthy at every stage of the SDLC.





